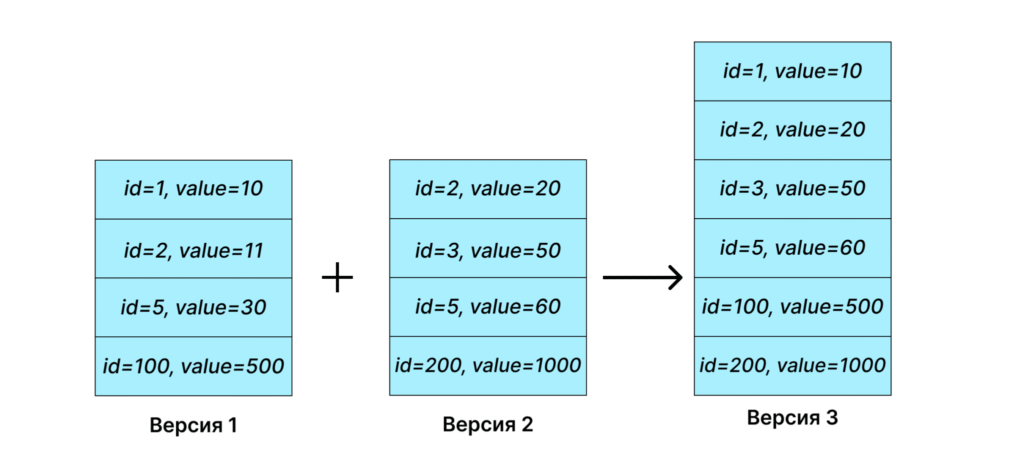
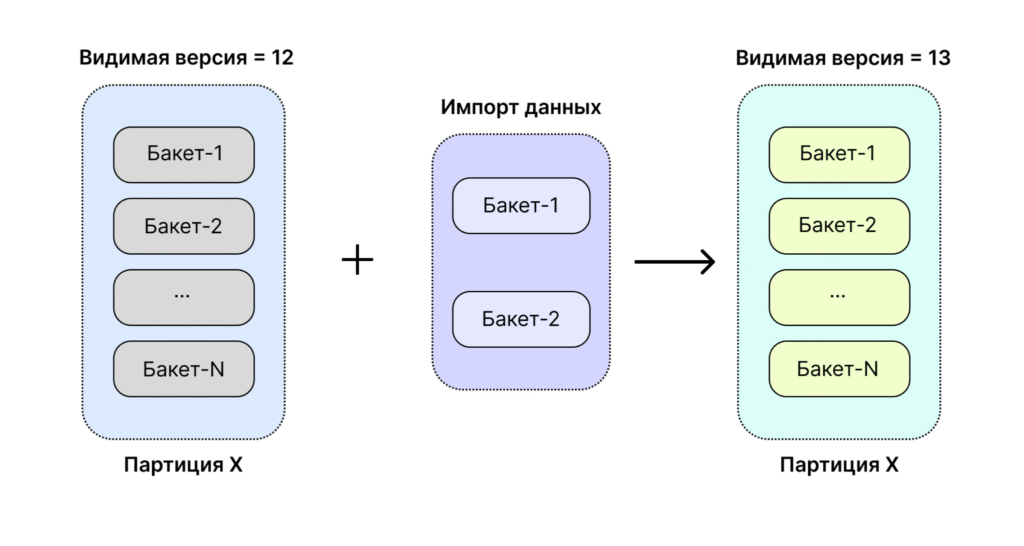
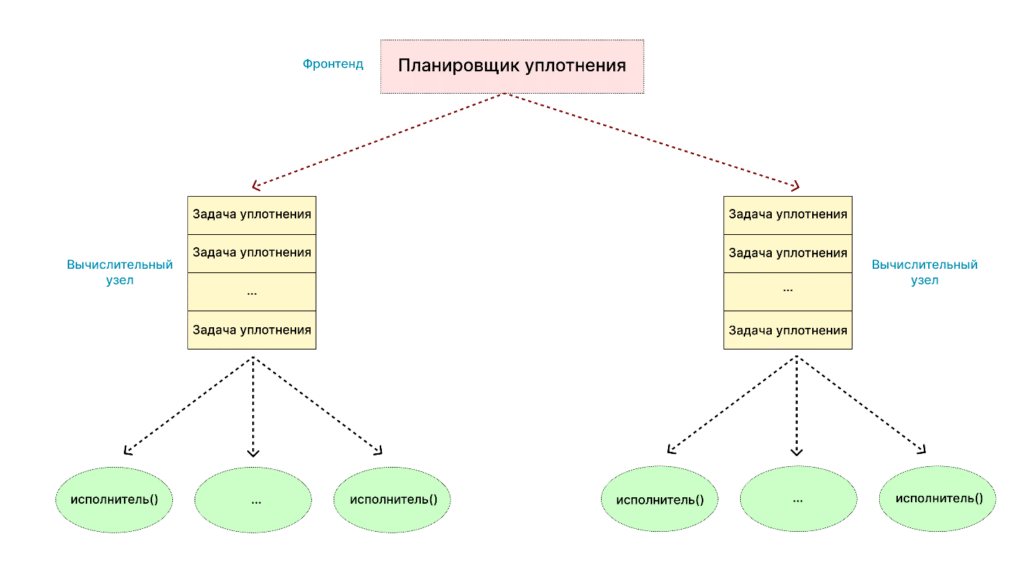
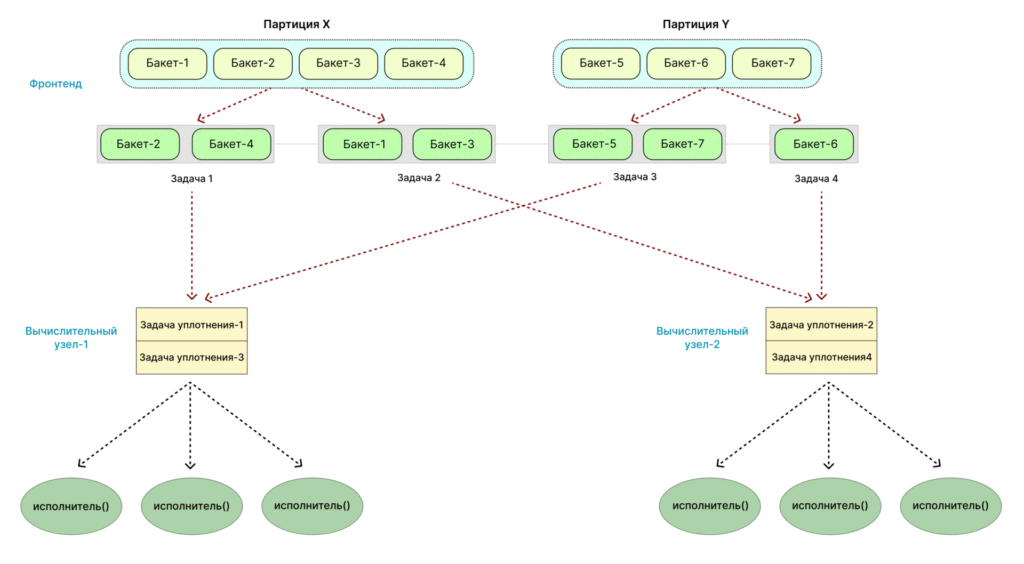
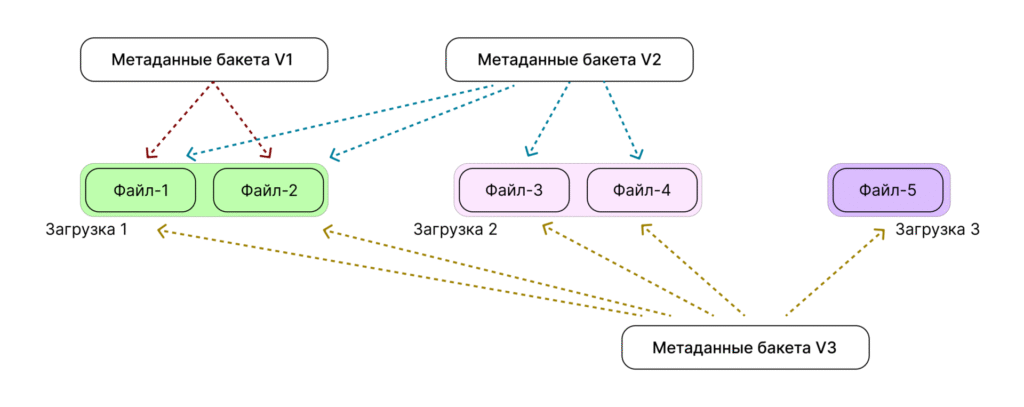
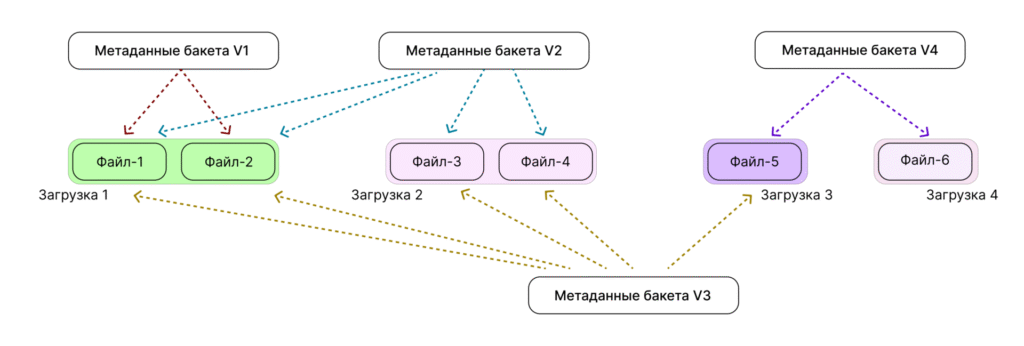
Примеры репликации данных
Репликация данных включает в себя несколько шагов: определение системы-источника и системы-приемника, выбор данных, которые нужно будет копировать, сроков (как часто необходимо делать обновление), определение метода репликации данных (полный, частичный), выбор ПО для осуществления репликации.
Исходя из бизнес-задач, которые стоят перед компанией, она выбирает то или иное решение для репликации. Например, Датафлот Репликация поддерживает широкий спектр источников, целей и платформ, упрощает операции чтения и записи, использует все доступные вычислительные мощности для создания реплики, обеспечивает готовность и доступность соответствующих данных в тот момент, когда они необходимы, обеспечивает доступ к данным в режиме реального времени, позволяет развивать передовую аналитику, машинное обучение и искусственный интеллект.
Датафлот Репликация – это промышленное решение, использующее журналы базы данных той системы, с которой работает, чтобы отслеживать все изменения, происходящие в данных в любой момент времени. Затем решение формирует блок данных, передавая его на сторону приемника данных (системы, в которой будут храниться копии). Системы-приемники могут быть разных типов в одном процессе репликации.
Решение позволяет обогащать реплику данных такими значениями, как дата изменения, тип операции, выполняемой на стороне источнике, значения бизнес полей до их изменения, и выполнять небольшие трансформации данных: преобразование типов, расчет значений атрибутов, обработка строк и т.п. Датафлот Репликация может отслеживать изменение структуры данных источника: если структура данных источника будет меняться, то изменится и среда той копии, которая создается.